Open RAN by disaggregation involves CU (Centralized Unit) and DU (Distributed Unit) virtualization. By decoupling hardware and software, Open RAN makes it possible to select different vendors and solutions for hardware and software and to manage their lifecycles separately. More specifically, this makes it possible to use COTS (Commercial off-the-shelf) general-purpose hardware in the RAN and avoid proprietary appliances.
COTS Hardware is not always the most efficient solution. It creates a potential vendor lock-in due to the omnipresent Intel-based x86 architecture. This is different from the vendor lock-in in the traditional RAN because COTS hardware has a more limited role than the proprietary appliances in a traditional RAN, but it still limits the choice and flexibility of operators. So COTS Hardware needs more hardware!
Change is underway with silicon vendors entering the market with Accelerators (e.g., Qualcomm, Marvell, Xilinx, Nvidia, and Intel) and SoC (e.g., Picocom) devices that are specifically designed and optimized for Layer 1 processing in the RAN. COTS remains the hardware of choice for the less intensive processing above Layer 1. Layer 1 processing is mostly limited to the O-DU and is the most complex and time-sensitive in wireless networks. COTS hardware is not optimized for this type of processing and, hence, not as efficient as dedicated hardware.

Especially in compute-heavy scenarios, hardware deployments can significantly accelerate any open RAN implementation and raw performance, reducing the number of CPU cores required and power consumption. Looking at the architecture for layer 1 acceleration, there are two fundamental approaches – look-aside acceleration and inline acceleration.
Look-aside acceleration
In the case of look-aside acceleration, the CPU is free to use its cycles to process other useful tasks, while the accelerator is working on the data to be accelerated. Once the CPU receives processed data back from the accelerator, it can switch back to the original processing context and continue the pipeline execution until the next function to be accelerated comes up.
Inline acceleration
In the inline acceleration case, a part of or the entire layer 1 pipeline can be offloaded to the accelerator, potentially allowing for a less data-heavy interface between the CPU and the accelerator. The acceleration solution can in this case be a mix of programmable and “hard” blocks, again there is a trade-off between flexibility and efficiency.
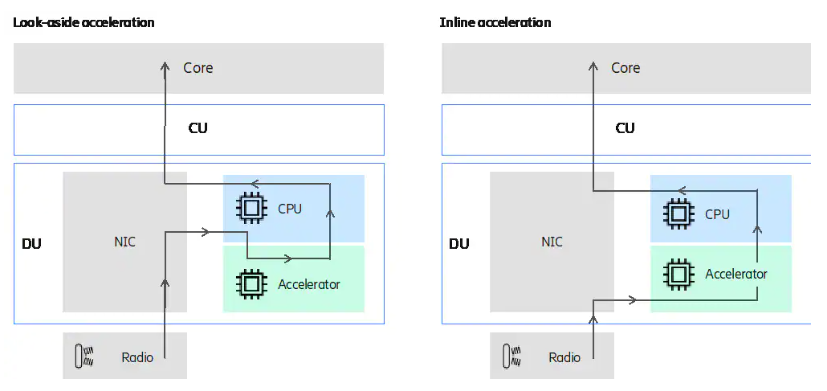
The principal difference between them is that in look-aside acceleration, only selected functions are sent to the accelerator, and then back to the CPU, while in inline acceleration parts of or the whole data flow and functions are sent through the accelerator. For higher bandwidth open RAN applications, full L1 processing offload may be required. In this case, an inline hardware accelerator is likely to deliver the best results with the lowest latency and minimum cores required.
Lookaside accelerators are less efficient but allow the COTS server to decide which functions should be sent to the accelerator. Inline accelerators use a simpler interface to the COTS server and process all Layer 1 functions.